Дипломная работа по теме:
“Интерактивная база данных по дендраклиматологии”
Работу выполнял: Кожановский Юрий 10 “А”
Научный руководитель:Маргаритов В.С.
Оглавление
Введение…………………………………………………….3
Первая глава
Дендроклиматология………………………………………5
Базы данных………………………………………………...7
Java и PHP.......................................................................15
Вторая глава
Описание программы……………………………………….21
Заключение………………………………………………….29
Приложение………………………………………………….30
Введение
Моя дипломная работа очень актуальна, потому что дендроклиматология – малоизученная и малоизвестная область биологии. Дендроклиматология пустила корни в летней школе в 2000 году, за это время накоплено большое количество данных.
В связи с этим появились цели структурировать базы данных, накопленные в течение всего периода изучения дендроклиматологии в летней школе. Моя основная задача заключается в создании web-ресурса с элементами php и java, а также базами данных, СУБД и удобным интерфейсом. Функциональность сайта достаточно проста, а именно на него можно загружать свои базы данных по дендроклиматологии и скачивать уже имеющиеся, что достаточно удобно для накопления сведений об этой науке и развитии ее.
Мои задачи — изучить литературу по базам данных(виды баз данных,объяснить выбор реляционной бд,рассказать почему сейчас выбираются реляционные бд,объяснить принцип работы бд),собрать все базы данных,находящиеся в архиве ЛШ, создать новую базу данных для удобного использования,изучить среды программирование php и java, разработать структуру интернет-ресурса и написать сначала альфа версию проекта ( только html),по мере изучения новых языков программирования будут постоянно добавляться новые элементы,такие как сценарии на java,возможности загрузить новых баз данных и скачивания их с сервера, и при необходимости выложить продукт моей деятельности на просторы интернета.
Структура моей работы будет выглядеть следующим образом:
Сначала ознакомлюсь с литературой, создам базы данных по дендроклиматологии, затем буду писать html версию своего ресурса,постепенно добавляя новые элементы, после этого соберу все воедино и продемонстрирую работу функциональность сайта,
План работы
1)Изучение дополнительной литературы (октябрь - декарь)
2)Написание введение и первой главы (январь)
3)Html-версия сайта + создание баз данных (январь - февраль)
4)написание 2 главы (март)
5)изучение java и php (апрель)
6) полноценная версия сайта (апрель -май)
7) 3 глава (возможно не будет)
8)Заключение (май)
Дополнительная литература:
1)С.Д.Кузнецов «Основы баз данных» 2007 г
2)Мишель Е. Дэвис и Джон А. Филлипс «Изучаем PHP и MySQL» 2008 г
3)Николай Прохоренок «HTML, JavaScript, PHP и MySQL. Джентльменский набор Web-мастера» 2010г
4)http://treering.ru/
5)Бешенков С.А., Ракитина Е.А. Информатика. Систематический курс. Учебник для 10 класса. М.: Лаборатория Базовых Знаний, 2001
1 ГЛАВА
1.1 Дендроклиматология
Дендроклиматология - раздел климатологии, исследующий изменения местных климатов в исторический период времени преимущественно по толщине годичных колец у многолетних древесных растений.
Это наука изучает взаимосвязь между годичными кольцами деревьев и метеорологическими величинами - температурой, осадками и солнечным сиянием. Возникла она на основе развития другой научной дисциплины - дендрохронологии, занимающейся определением возраста лесов путем исследования годичных колец деревьев.
Поскольку некоторые деревья живут многие сотни и даже тысячи лет (например, Мамонтове дерево в Калифорнии, как показал срез его пня, имело возраст более 3000 лет, а остистая сосна, росшая в предгорьях Уайт-Маунтинс в Северной Америке и спиленная в 1956 году, имела возраст более 4500 лет!), изучение их годичных колец позволяет судить о климате прошлого, о колебаниях температуры, режима осадков и солнечного сияния. Кроме того, сопоставление свежих срезов <�живых> деревьев со срезами погребенных деревьев более ранних времен открывает возможность продления хронологии изменения климата далеко за пределы возраста современных деревьев. Для Северной Америки и Средней Европы по годичным кольцам остистой сосны, дуба, лиственницы, ели и кедровой сосны восстановлена непрерывная хронология за период, превышающий 8000 лет, хронология с некоторыми пробелами - почти за 12 000 лет.
Численными методами с использованием ЭВМ была рассчитана количественная связь между данными ежегодных измерений характеристик древесины и летними температурами. Расхождение с фактическими данными оказалось меньше одного градуса. Удалось также сопоставить данные о колебаниях климата (а именно, о колебаниях температуры) с данными об изменениях фронта ледников в Альпах. Согласованность между всеми этими изменениями очень хорошая, что говорит о перспективности методов дендроклиматологии.
Методы исследования
Отбор проб производится с помощью ручного бура на определенном участке леса, отведенном для исследования. Образцы представляют собой пробы в виде цилиндра примерно 5мм в диаметре, взятые на одинаковой высоте по радиусу дерева. Дендролоклиматологи выбирают участок леса оптимально представляющий данный район. Например крутой скалистый южный склон может быть выбран для сбора данных о деревьях, произраставших в условиях недостатка воды или даже засухи. Темп прироста древесины на таком участке будет сильно зависеть от выпадения атмосферных осадков. Следовательно, очень важно знать основные характеристики участка и факторы, влияющие на рост древесины, до начала исследований, для правильной и точной интерпретации полученных результатов. Для презентативного статистического анализа необходимо как минимум 10 образцов. Образцы отправляются в лабораторию, где они подготавливаются к замерам ширины годовых колец. (Некоторые исследователи также измеряют плотность древесины, так как в некоторых случаях это помогает более правильно определить темп роста древесины). Точность измерения ширины годовых колец до 0,01мм. Все собранные данные записываются в компьютеризированную базу данных.
После чего все заносятся в базу данных ширины годовых колец, собранных на одном участке, обработаны, стандартизированы, и результаты представлены в хронологическом порядке. Процесс стандартизации включает в себя сглаживание кривых годовых колец для каждой серии образцов, этого можно добиться делением каждой ширины годового кольца на соответствующее отклонение кривой. Такой процесс дает возможность сравнения образцов с различным приростом, и может быть использован для избежания влияния на исследования нежелательных тенденций роста. Ширина годовых колец с возрастом дерева уменьшается по экспоненте, что показывает, что прирост древесины с течением времени снижается. Применив, обратную экспоненциальную зависимость исследователи могут рассчитать отклонение от среднего ожидаемого прироста древесины для данного образца без влияния возрастного фактора. Это отклонение далее используется для вычисления промежуточных результатов в исследованиях.
Обработка спилов
Возьмем спил дерева,затем его отшлифуем с помощью шлифовальной машинки,выберем 3 направления и с помощью миллиметровой бумаги
или специального программного обеспечения измерим расстояния от середины спила до его краев. Заносим результаты в базу данных.
Связь с другими науками
Дендроклиматология главным образом связана с 2 науками:дендрологией и дендрохронологией.
Наука, занимающаяся изучением древесных растений, носит название дендрология.
Дендрохронология — наука о методах абсолютной датировки исторических событий на основе использования специфических особенностей древесного прироста отдельных лет и их сочетаний. Методами дендрологии выявляются связи и закономерности, которые используются для ретроспективного восстановления климатических изменений в современных лесах за исторические периоды, в которые не велись инструментальные наблюдения за климатом.
Поэтому дендроклиматология тесно связана с дендрохронологией и дендрологией
1.2 Базы данных
База данных — представленная в объективной форме совокупность самостоятельных материалов , систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)
В традиционном понятии история возникновения баз данных начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Существует большая классификация бд(свыше 50 видов ),рассмотрим следующие:
Cетевые
Иерархические
Реляционные
И ерархические базы данных ерархические базы данных
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис
Сетевые базы данных
В середине 60-х годов появились оперативные сетевые БД. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию
С етевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между между записью-владельцем и записью-членом также имеет вид 1:N. етевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа.
К достоинствам сетевой модели относится очень высокая скорость поиска и возможность адекватно представлять многие задачи в самых разных предметных областях. Высокая скорость поиска основывается на классическом способе физической реализации сетевой модели - на основе списков. Более подробно о способах физической реализации сетевых СУБД можно почитать в монографиях Дж.Мартина и Дж.Ульмана. Можно обрнатиться и к технической документации доступных сетевых СУБД.
Главным недостатком сетевой модели, как, впрочем, и иерархичесокй, является ее жесткость. Поиск данных, доступ к ним, возможен только по тем связям, которые реально существуют в данной конкретной модели. В нашем примере с издательствами очень легко и быстро можно найти список всех статей, выпущенных издательством “Бухгалтерия и спорт”, но задача поиска издательств, в которых была опубликована статья “Влияние колец Сатурна на своевременную сдачу норм ГТО” будет требовать гораздо больших усилий. Причиной для подобных проблем, по мнению Е.Кодда), является “навигационный” характер сетевых СУБД. Другими словами, при поиске данных сетевая СУБД требует перемещаться только по существующим, заранее предусмотренным связям.
Реляционная база данных
Реляционные системы берут свое начало в математической теории множеств. Они были предложены в конце 1968 года доктором Э.Ф.Коддом из фирмы IBM, который первым осознал, что можно использовать математику для придания надежной основы и строгости области управления базами данных. Работы Эдгара Ф. Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику он также получил премию Тьюринга.
Реляционная база данных представляется пользователю как совокупность таблиц и ничего кроме таблиц. Вот пример реляционной БД.
Поставщики
ПС
|
Название
|
Статус
|
Город
|
Адрес
|
Телефон
|
1
|
СЫТНЫЙ
|
рынок
|
Ленинград
|
Сытнинская, 3
|
2329916
|
2
|
ПОРТОС
|
кооператив
|
Резекне
|
Садовая, 27
|
317664
|
3
|
ШУШАРЫ
|
совхоз
|
Пушкин
|
Новая, 17
|
4705038
|
4
|
ТУЛЬСКИЙ
|
универсам
|
Ленинград
|
Тульская, 3
|
2710837
|
5
|
УРОЖАЙ
|
коопторг
|
Луга
|
Песчаная, 19
|
789000
|
6
|
ЛЕТО
|
агрофирма
|
Ленинград
|
Пулковское ш.,8
|
2939729
|
7
|
ОГУРЕЧИК
|
ферма
|
Паневежис
|
Укмерге, 15
|
127331
|
8
|
КОРЮШКА
|
кооператив
|
Йыхви
|
Нарвское ш., 64
|
432123
|
|
|
Продукты
|
Наличие
ПР
|
Продукт
|
Белки
|
Жиры
|
Углев
|
K
|
Ca
|
Na
|
B2
|
PP
|
C
|
1
|
Говядина
|
189.
|
124.
|
0.
|
3150
|
90
|
600
|
1.5
|
28.
|
0
|
2
|
Судак
|
190.
|
80.
|
0.
|
1870
|
270
|
0
|
1.1
|
10.
|
30
|
3
|
Масло
|
60.
|
825.
|
90.
|
230
|
220
|
740
|
0.1
|
1.
|
0
|
4
|
Майонез
|
31.
|
670.
|
26.
|
480
|
280
|
0
|
0.
|
0.
|
0
|
5
|
Яйца
|
127.
|
115.
|
7.
|
1530
|
550
|
710
|
4.4
|
1.9
|
0
|
6
|
Сметана
|
26.
|
300.
|
28.
|
950
|
850
|
320
|
1.
|
1.
|
2
|
7
|
Молоко
|
28.
|
32.
|
47.
|
1460
|
1210
|
1500
|
1.3
|
1.
|
10
|
8
|
Творог
|
167.
|
90.
|
13.
|
1120
|
1640
|
1410
|
2.7
|
4.
|
5
|
9
|
Морковь
|
13.
|
1.
|
70.
|
2000
|
510
|
210
|
0.7
|
9.9
|
50
|
10
|
Лук
|
17.
|
0.
|
95.
|
1750
|
310
|
180
|
0.2
|
2.
|
100
|
11
|
Помидоры
|
6.
|
0.
|
42.
|
290
|
140
|
400
|
0.4
|
5.3
|
250
|
12
|
Зелень
|
9.
|
0.
|
20.
|
340
|
275
|
75
|
1.2
|
4.
|
380
|
13
|
Рис
|
70.
|
6.
|
773.
|
540
|
240
|
260
|
0.4
|
16.
|
0
|
14
|
Мука
|
106.
|
13.
|
732.
|
1760
|
240
|
120
|
1.2
|
22.
|
0
|
15
|
Яблоки
|
4.
|
0.
|
113.
|
2480
|
160
|
260
|
0.3
|
3.
|
130
|
16
|
Сахар
|
0.
|
0.
|
998.
|
30
|
20
|
10
|
0.
|
0.
|
0
|
17
|
Кофе
|
127.
|
36.
|
9.
|
9710
|
180
|
180
|
0.3
|
1.8
|
0
|
|
ПР
|
К_во
|
Стоим
|
1
|
108
|
429.84
|
2
|
0
|
0.00
|
3
|
73
|
274.61
|
4
|
39
|
97.46
|
5
|
61
|
111.83
|
6
|
88
|
206.60
|
7
|
214
|
83.08
|
8
|
92
|
82.80
|
9
|
0
|
0.00
|
10
|
77
|
46.30
|
11
|
46
|
51.70
|
12
|
13
|
34.96
|
13
|
54
|
51.14
|
14
|
91
|
43.77
|
15
|
117
|
189.92
|
16
|
98
|
96.14
|
17
|
37
|
166.50
|
|
|
Термин реляционный имеет следующие происхождение (лат. Relation — отношение) Это просто математический термин для обозначения неупорядоченной совокупности однотипных записей или таблиц определенного специфического вида, описанного выше.
Сравнение моделей данных
Возьмем 2 модели данных:реляционную и иерархическую
1)В иерархической модели связи между данными можно описать с помощью упорядоченного графа. В реляционной связь — отношения
2)Разный степень понятности для человека (иерархическая модель является громоздкой для обработки информации с достаточно сложными логическими связями, а также сложность понимания)
3)Иерархическая модель данных эффективно использует память ЭВМ и неплохие показатели времени выполнения основных операций над данными. Также меньший объем избыточной информации,нежели в реляционной
4)Распространенность ( Большинство СУБД сделано под реляционную модель данных,под иерархическую значительно меньше)
Свойства реляционной базы данных
всякому столбцу таблицы присвоено имя, которое должно быть уникальным для этой таблицы;
столбцы таблицы упорядочиваются слева направо, т.е. столбец 1, столбец 2, ..., столбец n. С математической точки зрения это утверждение некорректно, потому что в реляционной системе столбцы не упорядочены. Однако с точки зрения пользователя, порядок, в котором определены имена столбцов, становится порядком, в котором должны вводиться в них данные, если не предварять при вводе каждое значение именем соответствующего столбца
строки таблицы не упорядочены (их последовательность определяется лишь последовательностью ввода в таблицу);
в поле на пересечении строки и столбца любой таблицы всегда имеется только одно значение данных и никогда не должно быть множества значений (правда, это "атомарное" значение может быть достаточно объемным, например, таким, как рецепт блюда);
всем строкам таблицы соответствует одно и то же множество столбцов, хотя в определенных столбцах любая строка может содержать пустые значения (NULL-значения), т.е. может не иметь значений для этих столбцов;
все строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы;
при выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию
Преимущества
Главное достоинство таблиц — в их понятности. С табличной информацией мы имеем дело практически каждый день.
В реляционных БД строка таблицы называется записью, а столбец — полем. В общем виде это выглядит так: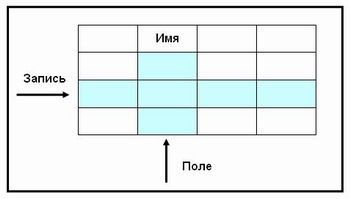
Каждое поле таблицы имеет имя. Например, в таблице «Игрушки» имена полей такие: НАЗВАНИЕ, МАТЕРИАЛ, ЦВЕТ, КОЛИЧЕСТВО.
Одна запись содержит информацию об одном объекте той реальной системы, модель которой представлена в таблице.
Например, одна запись о каком либо объекте — это информация об одной игрушке.
Поля — это различные характеристики (иногда говорят — атрибуты) объекта. Значения полей в одной строчке относятся к одному объекту. Разные поля отличаются именами. А чем отличаются друг от друга разные записи? Записи различаются значениями ключей.
Главным ключом в базах данных называют поле (или совокупность полей), значение которого не повторяется у разных записей.
В реляционных базах данных используются четыре основных типа полей:
числовой
символьный
дата
логический
Числовой тип имеют поля, значения которых могут быть только числами. Например, в БД «Погода» три поля числового типа: ТЕМПЕРАТУРА, ДАВЛЕНИЕ, ВЛАЖНОСТЬ.
Символьный тип имеют поля, в которых будут храниться символьные последовательности (слова, тексты, коды и т.п.). Примерами символьных полей являются поля АВТОР и НАЗВАНИЕ в БД «Домашняя библиотека»; поле ТЕЛЕФОН в БД «Школы».
Тип «дата» имеют поля, содержащие календарные даты в форме «день/месяц/год» (в некоторых случаях используется американская форма: месяц/день/год). Тип «дата» имеет поле ДЕНЬ в БД «Погода».
Логический тип соответствует полю, которое может принимать всего два значения: «да» — «нет» или «истина» — «ложь» или (по-английски) «true» — «false». Если двоичную матрицу представить в виде реляционной БД, то ее полям, принимающим значения «0» или «1», удобно поставить в соответствие логический тип. При этом «1» заменится на значение «истина», «0» — на значение «ложь».
От типа величины зависят те действия, которые можно с ней производить.
Например, с числовыми величинами можно выполнять арифметические операции, а с символьными и логическими — нельзя.
Немного о СУБД
Чтобы пользователь мог взаимодействовать с БД используются системы управления базами данных (СУБД)
Принципы построения систем управления баз данных следуют из требований, которым должна удовлетворять организация баз данных:
1) Производительность и готовность. Запросы от пользователя базой данных удовлетворяются с такой скоростью, которая требуется для использования данных. Пользователь быстро получает данные всякий раз, когда они ему необходимы.
2) Минимальные затраты. Низкая стоимость хранения и использования данных, минимизация затрат на внесение изменений.
3) Простота и легкость использования. Пользователи могут легко узнать и понять, какие данные имеются в их распоряжении. Доступ к данным должен быть простым, исключающим возможные ошибки со стороны пользователя.
4) Простота внесения изменений. База данных может увеличиваться и изменяться без нарушения имеющихся способов использования данных.
5) Возможность поиска. Пользователь базы данных может обращаться с самыми различными запросами по поводу хранимых в ней данных. Для реализации этого служит так называемый язык запросов.
6) Целостность. Современные базы данных могут содержать данные, используемые многими пользователями. Очень важно, чтобы в процессе работы элементы данных и связи между ними не нарушались. Кроме того, аппаратные ошибки и различного рода случайные сбои не должны приводить к необратимым потерям данных. Значит, система управления данными должна содержать механизм восстановления данных.
7) Безопасность и секретность. Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это права, от неавторизированной модификации (изменения) данных или их разрушения. Секретность определяется как право отдельных лиц или организаций решать, когда, как какое количество информации может быть передано другим лицам или организациям.
Одно из самых важных преимуществ современных СУБД состоит в логической и физической независимости данных. Рассмотрим базу данных,сделанную в СУБД DBASE. Она физически содержит, как минимум, три файла. В то же время эту же базу данных можно перенести в СУБД Microsoft Access, где она физически разместится в одном файле. При этом логическая организация данных не изменится.
Развитие аппаратного и программного обеспечения, средств телекоммуникаций привело к тому, что на сегодняшний день наметился переход от традиционных баз данных, хранящих числа и символы объектно-реляционным базам данных, где каждая запись может содержать данные со сложным поведением. Пример тому развитие internet-технологий. Современный настольные компьютеры и программы просмотра Web - браузеры - позволяют осуществлять поиск в глобальной сети и просматривать большую часть мультимедийных данных.
Существует огромное количество СУБД, например: Lotus Approach, Visual FoxPro, Borland Paradox, Borland dBase
Недостатки
Недостатком реляционной модели является ограниченность, предопределенность набора возможных типов данных атрибутов, их атомарность, что затрудняет использование реляционной модели для некоторых современных приложений. Частично эта проблема решается за счет введения больших двоичных объектов, но более полное и аккуратное решение используется в расширении реляционной модели - в объектно-реляционных СУБД.
Несмотря на то,что реляционная модель данных имеет свои недостатки,у нее есть много достоинств. Поэтому целесообразным будет использовать именно эту модель данных для реализации моего диплома.
1.3 JAVA и PHP
Java — объектно-ориентированный язык программирования, разработанный компанией Sun Microsystems (в последующем, приобретённой компанией Oracle). Приложения Java обычно компилируются в специальный байт-код, поэтому они могут работать на любой виртуальной Java-машине (JVM) независимо от компьютерной архитектуры. Дата официального выпуска — 23 мая 1995 года.
Java — так называют не только сам язык, но и платформу для создания и исполнения приложений на основе данного языка.
Изначально язык назывался Oak («дуб») и разрабатывался Джеймсом Гослингом для программирования бытовых электронных устройств. Впоследствии он был переименован в Java и стал использоваться для написания клиентских приложений и серверного программного обеспечения. Назван в честь марки кофе Java, любимого некоторыми программистами, поэтому на официальной эмблеме языка изображена чашка с дымящимся кофе. Существует и другая версия происхождения названия Java, а именно, Java это сленговое обозначение кофе (по имени одноименного острова, где производится популярный сорт кофе) с аллюзией на кофе-машину, как пример бытового устройства, для программирования которого изначально язык создавался.
Принцип работы JVM
Java Virtual Machine (сокращенно Java VM, JVM) — виртуальная машина Java — основная часть исполняющей системы Java, так называемой Java Runtime Environment (JRE). Виртуальная машина Java интерпретирует и исполняет байт-код Java, предварительно созданный из исходного текста Java-программы компилятором Java(javac). JVM может также использоваться для выполнения программ, написанных на других языках программирования. Например, исходный код на языке Ada может быть откомпилирован в байт-код Java, который затем может выполниться с помощью JVM.
JVM является ключевым компонентом платформы Java. Так как виртуальные машины Java доступны для многих аппаратных и программных платформ, Java может рассматриваться и как связующее программное обеспечение, и как самостоятельная платформа, отсюда принцип “написанное однажды, запускается везде” (write once, run anywhere). Использование одного байт-кода для многих платформ позволяет описать Java как “скомпилированное однажды, запускается везде” (compile once, run anywhere).
Особенности
Java-приложения могут быть выполнены на любом устройстве, для которого существует соответствующая виртуальная машина. Это связано с программой, обрабатывающей байтовый код и передающей инструкции оборудованию как интерпретатор. (JVM)
Это гибкая система безопасности,т.е исполнение программы полностью контролируется виртуальной машиной. Любые операции, которые превышают установленные полномочия программы (например, попытка несанкционированного доступа к данным или соединения с другим компьютером) вызывают немедленное прерывание
Однако есть недостаток Java:исполнение байт-кода виртуальной машиной может снижать производительность программ и алгоритмов, реализованных на языке Java.
Этот недостаток исправлен в следующих версий java, путем нововведений:увеличение скорости выполнения программ на Java.
По данным сайта shootout.alioth.debian.org, для семи разных задач время выполнения на Java составляет в среднем в полтора-два раза больше, чем для C/C++, в некоторых случаях Java быстрее, а в отдельных случаях в 7 раз медленнее.[ С другой стороны, для большинства из них потребление памяти Java-машиной было в 10-30 раз больше, чем программой на C/C++. Также примечательно исследование, проведённое компанией Google, согласно которому отмечается существенно более низкая производительность и бо́льшее потребление памяти в тестовых примерах на Java в сравнении с аналогичными программами на C++

Классификация платформ java
 
Java SE
 
Java EE
 
Java ME
 
JavaFX
 
Java Card
Применение платформы
Многие известные интернет-ресурсы реализованы с использованием Java технологий:RuneScape, Amazon, eBay, LinkedIn, Yahoo!
|

